Wstęp
Coraz więcej firm decyduje się na implementację bądź migrację swoich systemów do chmury, często w oparciu o architektury rozproszone jak popularne mikroserwisy. Czy zasadnie czy nie i z jakim skutkiem to opowieść na inny wpis. Niemniej jednak, takie sytuacje mają miejsce i jako konsultant oraz architekt, gdy rozmawiam z innymi programistami czy osobami odpowiedzialnymi za biznesy w firmach dla których pracuję, zauważam, że o ile większość moich rozmówców ma świadomość tego jak zbudować taki system z kilku mniejszych usług biznesowych, będących odzwierciedleniem kontekstów ograniczonych w organizacji (ang. Bounded Contexts) i jak połączyć je w całość, o tyle gdy przychodzi temat raportów i szeroko pojętego Business Intelligence to sprawy mają się różnie. W tym wpisie chciałbym pokazać z jakimi najczęściej wdrażanymi rozwiązaniami się spotykam, jakie mają wady/zalety oraz jak można to zrobić lepiej używając oczywiście chmury 😊.
Podejście nr 1 – serwis agregujący (ang. Aggregation Service)
Jak sama wskazuje to rozwiązanie polega na wprowadzeniu do systemu nowej usługi raportowej, której zadaniem jest wyciąganie danych z pozostałych usług i łączenie ich (agregacja) w jeden model danych, który zostanie użyty do wygenerowania raportu. Przykładowy proces został przedstawiony na poniższym diagramie.
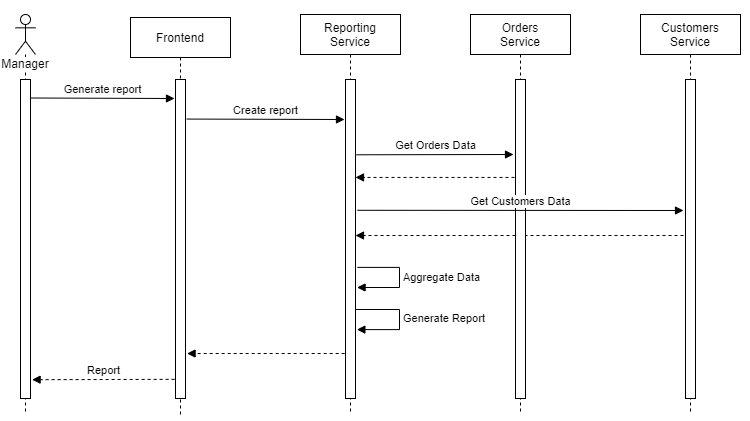
Pomimo prostoty tego rozwiązania, największą jego wadą jest komunikacja synchroniczna. Serwis raportowy musi odpytać API każdej usługi, której dane są potrzebne do wygenerowania raportu. W naszym przypadku są to dwie usługi: Orders i Customers, ale w rzeczywistym systemie z pewnością będzie ich więcej. Ponieważ są to żądania synchroniczne (tutaj HTTP, ale może to też być gRPC lub SOAP zwłaszcza gdy organizacja używa systemów legacy), to musimy czekać na zakończenie każdego z nich i następnie poskładać wszystkie dane w jedną całość co będzie miało duży wpływ na wydajność i responsywność systemu. Raz, że będziemy tracić czas na oczekiwanie na pobranie danych, transformację do modelu raportowego i generowanie wynikowego raportu, a dwa, że będziemy niepotrzebnie obciążać inne usługi poprzez każdorazowe odpytywanie ich API. Oczywiście w niedużych systemach, gdzie raporty nie są złożone i nie są generowane zbyt często to rozwiązanie się sprawdzi bardzo dobrze. Niestety wraz z rozwojem systemu, przyrostem użytkowników i wzrostem złożoności raportów będziemy coraz bardziej obserwować spadek wydajności. Jedni w takiej sytuacji radzą sobie poprzez skalowanie systemu w górę lub wszerz, inni decydują się na zmianę architektury i wdrożenie kolejnych usług, tym razem odpowiedzialnych za wyciąganie danych i zapisywanie ich w dedykowanej bazie raportowej.
Podejście nr 2 – Data Workers
To podejście zmienia sposób komunikacji usługi raportowej z pozostałymi poprzez wprowadzenie dodatkowych komponentów, tak zwanych data workerów, których zadaniem jest wyciąganie danych z innych usług i zapisywanie ich w dedykowanej bazie, skąd są później odczytywane przez usługę raportową przy generowaniu raportu. Dzięki takiemu rozluźnieniu komunikacji, usługa raportowa nie musi tracić czasu na odpytywanie innych usług i agregację danych tylko może się skupić na generowaniu raportu na podstawie jednego źródła, zawierającego wszystkie potrzebne informacje.
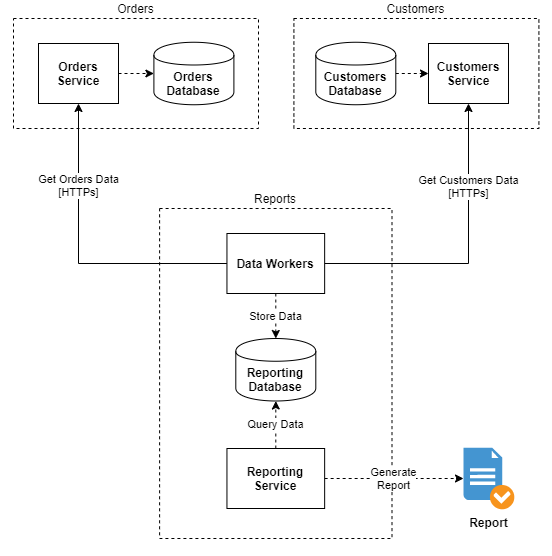
Data workery pozwalają również na filtrowanie, oczyszczanie i normalizację danych, przez co usługa raportowa nie musi robić później skomplikowanych zapytań. Jeżeli komuś skojarzyło się to z procesem ETL (Extract, Transform, Load) to bardzo dobrze bo koncepcyjnie jest to uproszczona implementacja tego procesu.
Podejście nr 3 – zdarzenia (ang. Events)
Innym podejściem do tematu raportów jest architektura oparta o zdarzenia. Tutaj nie mamy usług, które odpytują inne usługi o dane, tylko usługi same powiadamiają siebie nawzajem o tym, że coś się wydarzyło. Koncepcyjnie rozwiązanie możemy zaprezentować następująco:
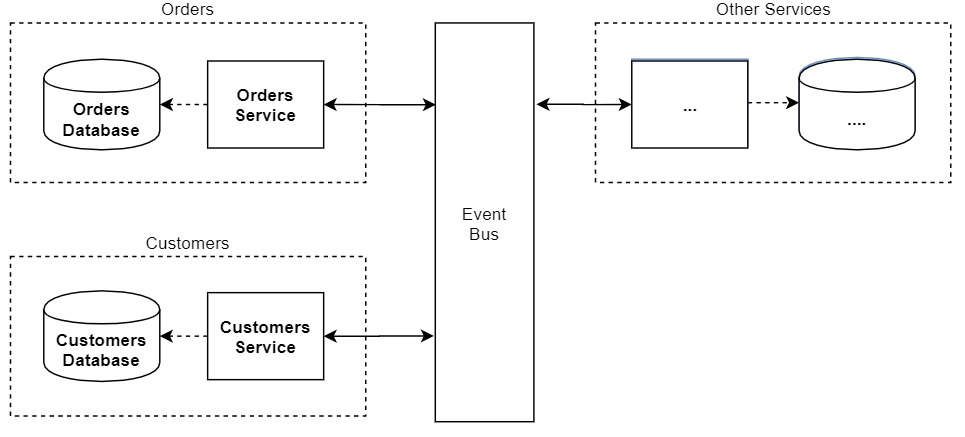
Zacznijmy od tego czym jest zdarzenie. Zdarzenie modeluje sytuację która miała miejsce w przeszłości i się zakończyła – jest faktem. Przykładowymi zdarzeniami w systemie są sytuacje gdy:
- Utworzono użytkownika
- Zatwierdzono zamówienie
- Opłacono zamówienie,
- Anulowano rezerwację, itd
Takie zdarzenia niosą ze sobą ogrom informacji. Odpowiednio zaprojektowane usługi zorientowane na zdarzenia pozwalają na analizowanie historii działania usługi (event log), śledzenie aktywności, czy nawet przywracanie stanu usługi do momentu z przeszłości. Architektura oparta o zdarzenia (ang. Event Driven Architecture) jest szeroko stosowana w wysokowydajnych systemach o architekturze mikrousługowej do komunikacji usług między sobą. Usługi zamiast komunikować się synchronicznie poprzez HTTP, SOAP lub gRPC, publikują i subskrybują zdarzenia (Publish/Subscribe Pattern). W tym celu wymagany jest komponent, który będzie obsługiwał wiadomości, zwykle jest to message broker (RabbitMQ, ActiveMQ, Azure Service Bus itd.), ale może też to być magazyn zdarzeń (ang. Event Store) taki jak Kafka.
Implementacja architektury opartej o zdarzenia nie jest łatwa. Wymaga bezpiecznej i niezawodnej infrastruktury – awaria Message Brokera lub Event Store uziemia cały system. Bardzo łatwo o duplikację zdarzeń np. w wyniku awarii którejś z usług. Przykładowo usługa reagująca na zdarzenie obciążające użytkownika finansowo, może otrzymać to samo zdarzenie dwa razy i naliczyć opłaty podwójnie. Do tego dochodzą problemy związane ze spójnością danych (Eventual Consistency), transakcyjnością, czy orkiestracją lub choreografią zdarzeń w procesy biznesowe.
Oczywiście nikt z nas nie zdejmie odpowiedzialności za nieprawidłowe zaprojektowanie systemu w wyniku którego może dojść do błędów w systemie, niemniej jednak możemy część obowiązków związanych z utrzymaniem i zarządzaniem infrastrukturą przerzucić na kogoś innego, a mianowicie dostawcę chmury. Obecnie każda wiodąca chmura posiada usługi pozwalające na implementację rozwiązań w architekturze opartej o zdarzenia przy użyciu bezpiecznej, odpornej na awarie i skalowalnej infrastruktury. My w tym czasie zamiast skupiać się na zapewnieniu ciągłości działania i niezawodności infrastruktury możemy skupić się na właściwym modelowaniu i implementacji procesów biznesowych, wykorzystując takie narzędzia jak Event Storming, Domain Driven Design czy Test Driven Development.
Przykładowe wdrożenie usługi raportowej do systemu uruchomionego w MS Azure i opartego o architekturę mikrousługową mogłoby wyglądać następująco:
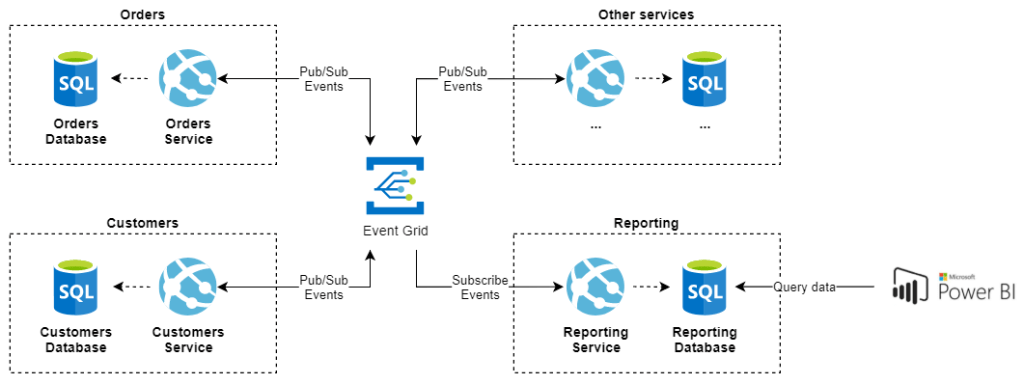
W tym rozwiązaniu usługi komunikują się ze sobą za pomocą usługi Event Grid w modelu Publish/Subscribe. Dzięki temu, wykorzystujemy istniejącą infrastrukturę komunikacyjną i podpinamy kolejną usługę – Reporting Service, której głównym zadaniem będzie nasłuchiwanie na zdarzenia z pozostałych usług i aktualizowanie danych raportowych na podstawie przychodzących zdarzeń z pozostałych usług. Dane te mogą potem zostać wykorzystane przez narzędzia do wizualizacji danych jak SQL Server Reporting Services czy PowerBI. Dzięki zastosowaniu komunikacji asynchronicznej w modelu Publish/Subscribe pomiędzy usługami, jest to stosunkowo mało inwazyjne rozwiązanie, które w niewielkim stopniu wymaga modyfikacji pozostałych usług.
Rozwiązanie to, mimo, że relatywnie proste w implementacji ma swoje ograniczenia, mianowicie usługa raportująca jest odpowiedzialna za przetwarzanie napływających zdarzeń, to znaczy filtrowanie, walidację, transformację i zapis danych. W jednym z kolejnym wpisów zobaczymy w jaki sposób możemy wykorzystać usługi analityczne i big data MS Azure do budowy wysokowydajnego silnika raportowego wykorzystującego strumienie zdarzeń, analizę i wizualizację danych w trybie rzeczywistym.
Do usłyszenia!
